Introduction
Boggle is a game where an N-by-N grid of letters is drawn randomly. Players then try and form words by connecting letters with their adjacent neighbours, where adjacency is defined as the immediate vertical, horizontal, and diagonal letters.

Boggle Solver employs a recursive algorithm for first finding every possible path on the board, and then checking if the word it forms is in a dictionary. Mathematically, the algorithm finds every simple, directed path on an N-by-N King graph. Simple, meaning without intersection. Directed, meaning direction matters beginning to end. And King graph, or King grid, because valid moves are the same as the King in a game of chess. These terms come from Graph Theory, but it’s not required at all to understand the problem and this solution. For interest, the number of paths on the board is fixed, given N, and we know up to a 10-by-10 grid. The sequence grows astonishingly fast! You can see for yourself at the Online Encyclopedia of Integer Sequences number A236690.
Algorithm
The 4-by-4 toy board above is a (poor) example of a game. In reality, the letters are randomly drawn, but this ordered look will help us follow the algorithm later. To imagine what constitutes a valid word candidate, we can pretend the player started at the top left, position (0, 0) by convention, and connected letters to form the path below. Since there are more options to explore at the end of this path, we will call it non-terminating.

The word candidate this path forms is ‘ABCHKO’, with the path ending on ‘O’ and thus the current position is (2, 3) denoted by the blue circle.
With the basics of Boggle out of the way, understanding the algorithm is fairly straight forward. The general structure of it is:
1) Given a starting position, the current word candidate, and a record of which tiles have been used, recurse into each available neighbour.
2) When each available neighbour has been branched to, check if the word candidate exists in a dictionary and return.The starting position is a simple (X, Y) coordinate on the board, zero-indexed from the top-left by convention. The current word candidate is simply the string formed along the path. The only complicated part is the record of used tiles. For this, the algorithm stores an N-by-N, Boolean grid where ‘0’ denotes an available tile, and ‘1’ denotes a used one.
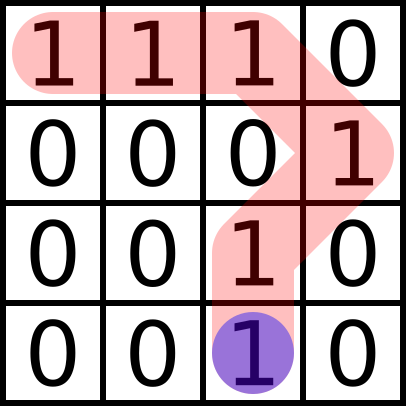
So, in the above path, the algorithm would recursively branch into the ‘J’, ‘L’, ‘N’, and ‘P’ tiles before checking ‘ABCHKO’. If it chose ‘J’, for example, the next level of recursion would branch out to ‘E’, ‘F’, ‘G’, ‘I’, ‘M’, and ‘N’ before finally checking ‘ABCHKOJ’. Because checking doesn’t occur until all avenues of branching have been explored, the algorithm searches in a breadth-before-depth approach.
One of the possible paths is pictured below.

At this point, the algorithm has no more valid moves, and thus fails to recurse further. We will call this a terminating path. It will check ‘ABCHKONJIM’ for validity, and return to the previous level of recursion (the ‘I’, which may then recurse again into ‘E’ or ‘F’.)
Occasionally, it will stumble upon a path which is found in the dictionary. A match!

Implementation
Boggle Solver requires only two pieces in total: a dictionary that is fast to search, and a recursive function that steps through the board.
According to the Python wiki,
…doing a membership search on a list has an average time complexity of O(n), where a dictionary can do it in O(1). The latter is known as constant-time and is the best it gets. Even a dictionary’s worst-case scenario only degenerates down to a list’s average performance.
Python wiki
Clearly, storing our dictionary in memory, in a set, is the way to go.
To accomplish this, we’ll declare a Big Bad Global™ set called dictionary, and fill it from the specified dictionary file on disk.
dictionary = None
[...]
def dict_init(path):
global dictionary
with open(path) as word_file:
dictionary = set(word_file.read().split())
return That is to say, given the path to a word list on disk, read its contents, split it into a list at the newline characters, convert it to a set called dictionary to remove duplicates and speed-up searching. dictionary is then a fast, searchable container to test against.
word_list = []
[...]
def check_word(word):
dprint('Checking: ' + word)
if (dictionary == None):
print('[ERROR] DICTIONARY HAS NOT BEEN INITIALISED!')
exit()
if (len(word) >= 3 and word not in word_list and word in dictionary):
return True
else:
return False Checking a word candidate is fairly straight-forward. First, a sanity check is performed to make sure the dictionary was initialised in the first place, then the second conditional tests:
- If the word length is greater than or equal to 3 (a Boggle rule, not a technical limitation.)
- That the candidate is unique; that the candidate hasn’t been found before.
- That the candidate exists in the dictionary.
Searching word_list is technically not optimised since a list has been shown to be slower than a set, but the size of word_list will be orders of magnitude smaller than dictionary so performance isn’t an issue, and a list gives us indexing which a set does not.
The last remaining piece is the recursive function. This is by far the most complicated piece of the whole program. Breaking it down into chunks should make it easier to understand.
def step(board, mask, position, word):
dprint('New iteration on ' + word + ' ' + str(mask))
# Set up the step.
x = position[0]
y = position[1]
lenx = len(board[0])
leny = len(board) Since step() can be called at any position and time, the first step is to decode the input parameters to build a current state. The (X, Y) coordinate is extracted from the position tuple, and the board dimensions are calculated. The (never changing) game board, the current mask, and the word candidate so far are immediately available as input parameters. At this point, the algorithm knows where it is, what it has, and where it can go. The next step is to recurse into these available paths.
if ( (x-1 >= 0) and (mask[y][x-1] == 0) ): # LEFT
submask = copy.deepcopy(mask)
submask[y][x-1] = 1
subword = word + board[y][x-1]
dprint('Got: ' + word + ' ' + 'Trying: ' + subword)
step(board, submask, (x-1, y), subword) There are eight, nearly identical conditional statements, one for each of the possible directions to recurse into. The tile is only a valid move, however, if it is on the board and hasn’t been visited before. To move left, for example, the position x-1 must be greater than or equal to 0, meaning not off the left edge of the board. That position, mask[y][x-1], must also be unused and therefore have a 0 in the mask.
If these conditions are not met, it’s an invalid move and the algorithm moves on to look elsewhere. If it is a valid move, a submask is created as a copy of the current mask, and the left tile is marked as used in submask. subword is created as the concatenation of the current word candidate, and the leftwards letter. Lastly, the step() function calls itself with the same board, but updated position, submask, and subword and the process starts over at this next recursion level down.
Another direction is shown so you can see the similarities and differences between moving left, and moving up-right.
if ( (x+1 < lenx) and (y-1 >= 0) and (mask[y-1][x+1] == 0) ): # UP-RIGHT
submask = copy.deepcopy(mask)
submask[y-1][x+1] = 1
subword = word + board[y-1][x+1]
dprint('Got: ' + word + ' ' + 'Trying: ' + subword)
step(board, submask, (x+1, y-1), subword) After all of the eight possible, adjacent tiles have been explored, the algorithm checks if the word candidate at this level is a valid move.
global word_candidates, word_count
word_candidates += 1
if ( check_word(word) ):
word_count += 1
word_list.append(word)
dprint('Found:' + word.upper())Every check constitutes another word candidate, but only words found in the dictionary count as solutions. Every time check_word() finds word in dictionary, it returns True and word gets counted and appended to word_list.
Something you may have noticed is the dprint() function which doesn’t exist in Python. It’s simply a trivial debugging function I wrote because I was too lazy to implement proper tracing in such a small program.
DEBUG = False
[...]
def dprint(msg):
if DEBUG:
print('[DEBUG]:', msg)
return The remainder of the program is not much more than boiler-plate and glue code. The only other piece worth talking about is the two-dimensional loop that begins a recursion tree rooted at each of the N2 tiles on the board.
if __name__ == '__main__':
leny = len(board)
lenx = len(board[0])
dict_init(dictionary_path)
print('Beginning search. This could take a few minutes...')
start = time.time()
for y in range(leny):
for x in range(lenx):
mask = [[0] * lenx for i in range(leny)]
mask[y][x] = 1
step(board, mask, (x,y), board[y][x])
end = time.time()
word_list.sort(reverse=True, key=len)
for word in word_list:
print(word)
print('Word candidates:', word_candidates)
print('Word count:', word_count)
print('Time:', round(end-start, 3), 'seconds.')This initialisation code is responsible for initialisation the dictionary set, timing the whole solution crunch, creating a 2D mask of zeros with a one in the starting position, and kicking off the step() function with this seed. Lastly, it sorts word_list, the found words, by length for user experience, and prints them out with some statistics. And it’s done!
The complete code won’t be posted here since it’s likely to change, but it will always be available in my repository. There are some features I’d like to add that will come in the future when Hell freezes over when I have some free time to work on it.
You can download the source code here!
Future Features
Following is a list of features I am working on adding to the solver.
- Multi-processing, to help speed up solution time by leveraging multiple processors.
- Advanced rules, like those in Microsoft’s Wordament where some tiles are only valid at the beginning or end.